The other day, I would have needed a couple of curved arrows on my plot, so I started to work out a method to get what I wanted. This, however, turned out to be rather interesting, so I thought that I would share the details with you.
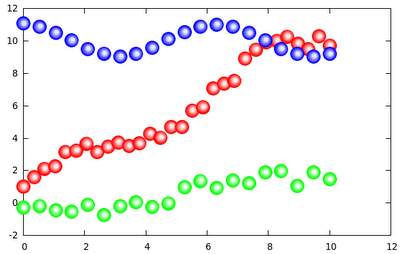
First, we should just define what I mean by a curved arrow. Perhaps, the easiest way to define it is to show a plot, similar to this
In gnuplot, when one wants an arrow, one can invoke the following command:
set arrow from 0,0 to 1,1
or something similar. This will produce a straight arrow from (0,0) to (1,1). But what if we wanted to have an arrow, which is not straight. Well, in this case, we set a very short arrow, and draw a curve separately. The key to this is to set the arrow in such a way that it is tangential to the curve at the end point. It is easy to see that the following script would just do that
reset
unset key
eps = 0.001
set style arrow 1 head filled size screen 0.03, 15, 45 lt -1
cut(x,x1,x3) = ((x >= x1 && x <= x1 + (1.0-eps)*(x3-x1)) ? 1.0 : 1/0)
f(x) = 0.5+(x-1)*(x-1.2)*(x-1.4)
x1 = 0.5
x3 = 1.95
new_x = x1 + (1.0-eps)*(x3-x1)
set arrow from new_x, f(new_x) to x3,f(x3) as 1
plot [0:3] sin(x) with point ps 1 pt 6, f(x)*cut(x,x1,new_x) with line lt -1
First, we define an arrow style that we will use later. The arrow will be 0.03 screen sizes big, and the two angles determining the shape of the head are 15, and 45 degrees, respectively. Finally, we stipulate that the arrow be black, i.e. linetype -1. Then we define a window function, cut, which depends on the two end points, x1, and x3 (the reason for 3 will become clear soon), and the curve, f(x). In our plot, beyond what we actually want to plot, we will also plot f(x), but only between x1, and new_x, where new_x is a bit off with respect to the second end point. The degree of "bitness" is given by eps, which was defined at the beginning. However, before we actually plot anything, we have got to set the arrow, between new_x, f(new_x), and x3, f(x3). This construction ensures that the arrow is tangential to the curve.
At this point, we are ready to plot, which we actually execute in the next, and last line.
What we have created is great, but there are problems: first, we have to define our function, f(x), beforehand, we have to set the arrows by hand, and we also have to add the appropriate lines to our plot command. Quite tedious. There has got to be a better way!
For the say of example, let us suppose that we want a curved arrow that, say, connects (0,0) and (1,1) via a parabola that passes through the point (0.5, 0.25). If we are really pressed for it, we could do the following: First, we have to figure out the parameters of our parabola. In this case, it is quite easy, for it is nothing but x*x. Then we would draw a parabola between (0,0), and (0.99, 0.9801), and then draw an arrow from (0.99, 0.9801) to (1,1).
First, let us see, how we figure out the parameters of our parabola! We have two end points, and a "control" point, i.e., we have to solve the following set of equations
y1 = a*x1*x1 + b*x1 + c
y2 = a*x2*x2 + b*x2 + c
y3 = a*x3*x3 + b*x3 + c
for the unknown a, b, and c. You can convince yourself that the following will do
denom(x1, x2, x3) = x1*x1*(x2-x3) + x1*(x3*x3-x2*x2) + x2*x3*(x2-x3)
A(x1,y1,x2,y2,x3,y3) = ( (x2-x3)*y1 + (x3-x1)*y2 + (x1-x2)*y3 ) / denom(x1,x2,x3)
B(x1,y1,x2,y2,x3,y3) = ( (x3*x3-x2*x2)*y1 + (x1*x1-x3*x3)*y2 + (x2*x2-x1*x1)*y3 ) / denom(x1,x2,x3)
C(x1,y1,x2,y2,x3,y3) = ( (x2-x3)*x2*x3*y1 + (x3-x1)*x1*x3*y2 + (x1-x2)*x1*x2*y3 ) / denom(x1,x2,x3)
a = A(x1,y1,x2,y2,x3,y3)
b = B(x1,y1,x2,y2,x3,y3)
c = C(x1,y1,x2,y2,x3,y3)
We have done most of the hard work, the only thing that remains is how we "automate" this whole machinery, i.e., what do we do, if we have several arrows that we want to set. Again, as so many times in the past, we will utilise this new notion of function definition: the fact that a function is not only a x -> f(x) mapping, but this mapping, and a set of possibly unrelated instructions. What we will do is to define a "function" that sets our arrows, and, as the supplementary instruction, augments the plot command accordingly. First, let us take the following function definition
arrow(x1,y1,x2,y2,x3,y3) = (new_x = x1 + (1.0-eps)*(x3-x1), \
a = A(x1,y1,x2,y2,x3,y3), b = B(x1,y1,x2,y2,x3,y3), c = C(x1,y1,x2,y2,x3,y3), \
PLOT = PLOT.sprintf(", cut(x,%f,%f)*(%f*x*x+%f*x+%f) with lines lt -1", x1, x3, a, b, c), \
ARROW.sprintf("set arrow from %f, %f to %f,%f as 1; ", new_x, a*new_x*new_x + b*new_x + c, x3, y3))
and try to understand what it does! For a start, it takes 6 arguments, which are nothing but the coordinates of the end points, and the control point. Then, it defines new_x, which we have already seen in the first example. In the next step, based on the 6 input arguments, calculates the three parameters of our parabola, and in the next line, adds the plot of this parabola to a string called PLOT. When adding to PLOT, we simply use the sprintf function. In the last line, we concatenate a string called ARROW, and another one, produced by another sprintf. It is easy to see that this sprintf returns the definition of an arrow between new_x, f(new_x), and x3, f(x3). We should also note that this line is the last line, which consequently means that whatever happens here is returned.
At this point we are really done, we only have to "populate" our plot. The full script takes on the form
reset
unset key
eps = 0.01
set style arrow 1 head filled size screen 0.03, 15, 45 lt -1
cut(x,x1,x3) = ((x >= x1 && x <= x1 + (1.0-eps)*(x3-x1)) ? 1.0 : 1/0)
denom(x1, x2, x3) = x1*x1*(x2-x3) + x1*(x3*x3-x2*x2) + x2*x3*(x2-x3)
A(x1,y1,x2,y2,x3,y3) = ( (x2-x3)*y1 + (x3-x1)*y2 + (x1-x2)*y3 ) / denom(x1,x2,x3)
B(x1,y1,x2,y2,x3,y3) = ( (x3*x3-x2*x2)*y1 + (x1*x1-x3*x3)*y2 + (x2*x2-x1*x1)*y3 ) / denom(x1,x2,x3)
C(x1,y1,x2,y2,x3,y3) = ( (x2-x3)*x2*x3*y1 + (x3-x1)*x1*x3*y2 + (x1-x2)*x1*x2*y3 ) / denom(x1,x2,x3)
ARROW = ""
PLOT = "p [0:3] sin(x) w p ps 1 pt 6"
arrow(x1,y1,x2,y2,x3,y3) = (new_x = x1 + (1.0-eps)*(x3-x1), \
a = A(x1,y1,x2,y2,x3,y3), b = B(x1,y1,x2,y2,x3,y3), c = C(x1,y1,x2,y2,x3,y3), \
PLOT = PLOT.sprintf(", cut(x,%f,%f)*(%f*x*x+%f*x+%f) with lines lt -1", x1, x3, a, b, c), \
ARROW.sprintf("set arrow from %f, %f to %f,%f as 1; ", new_x, a*new_x*new_x + b*new_x + c, x3, y3))
ARROW = arrow(0,0,1,1.5,pi/2,1.03)
ARROW = arrow(0,0,1,0.3,pi/2,0.97)
eval(ARROW)
eval(PLOT)
which would result in the graph shown here:
Now it is clear what was PLOT: it is nothing, but the actual plot that we want to have. This is the string to which we concatenate our parabolae, one by one, every time we define a new arrow. After we defined all our arrows, we have two strings, ARROW, and PLOT. As such, they are no good, they will become instructions only when we evaluate them. That is what we do in the last two lines.
I would like to point out that my main reason for posting this was not that it can be used for creating curved arrows, but that this method is quite general. First, we can add to the plot, if that is needed, without having to keep track of all the tiny details. Second, the set command can be "fooled" by using the sprintf function. With the help of the string augmentation and the eval command, we can actually use parameters in our set instruction very efficiently.
Well, this is for today. I am waiting for suggestions as to what we should discuss next time. Cheers,
Zoltán