Since I am a Linux fan, I am quite fine with calling various scripts from gnuplot: pipes are rather convenient, and I can write a small script which does the data processing. But I see the downside of it, too: these solutions (while you can make it work under windows) will require extra steps, if not run under linux. I also understand that you might not want to delve into the nuances of gawk, for instance. So, I was wondering whether we could do everything in gnuplot, without relying on something external. And the answer is, yes, we can! (Otherwise, I wouldn't be writing this post at all...) What we are going to do is probably the dirtiest of hacks, for we will use a function of gnuplot, which was never intended to be used in such a ramshackle way. But we want to produce graphs, and this is not a coding beauty contest, after all!
If you recall, we had a data file with two columns: one designating years, the other one containing the values belonging to those particular years. Something like this, which we will call pie.dat:
1989 0.1 1990 0.2 1991 0.2 1992 0.05 1993 0.15 1994 0.3
You might also recall that the way in which we produced the pie chart was to plot arcs of a circle, the parameters determined by the second column. Now, the problem was (and this is why we had to use an foreign script) that those parameters cannot be set at run-time, so to speak, we had to hard-wire them into the gnuplot script. So, the question is really how we can access individual values of a data file, say, the 5th number in the 2nd column, and then do this repeatedly. The snag is that gnuplot hasn't a dedicated function to perform this task, so we have to look for a function that is dedicated to something else. Since there are not too many gnuplot functions that operate on a file, we can easily find the one that "returns" a value. We will use the fit function, and use the fitting parameter as a means of returning the sought-after value from the file. I know, I know! This is the ultimate abuse of 'fit', and we shouldn't do this at all! But what the heck! You haven't got to tell anyone how you produced that bloody figure!
Now, we have to find a proper fitting function. Remember, we want to pick the value of a particular number in the second column, say. Well, being a physicist, I would say that the Dirac-delta will do the job. However, we have to soften our stance a bit, and use something that is gnuplot-friendlier. For better or worse, I will choose the following function
f(x,a)=(x>a-0.5?(x<a+0.5?b:0):0)
You can recognise our old friend, the ternary operator, making its appearance twice in the definition of f(x,a). So, we first check, if the value 'x' is larger, than a-0.5. If so, we check whether it is smaller, than a+0.5. If this condition is fulfilled, we assign the value 'b', otherwise 0. By plotting it, you can see it for yourself that this function is a rectangle of height 'b' and width 1, centred on 'a', and 0 everywhere else. 'b' is going to be our fit parameter. Now, if you fit this function as
fit [0:7] f(x,2) 'pie.dat' u 0:2 via b print b
then 0.2 will be printed. But that is the value of the 3rd number in the second column of pie.dat! (The rows are numbered starting with 0, that is why 2 means the 3rd row.) Since the value 'b' can be used in any subsequent expressions, definitions etc. as a number, we have found a way to extract any single number from any data file.
In order to proceed, we have to find a method to step through the rows of a column, one by one. For this purpose, we will use the reread command of gnuplot. You can learn the basic idea by issuing ?reread and ?if. 'reread' just repeatedly reads the file invoked by the last load command, and we can use 'if' to set some criterion as to how many times this repeated loading should take place. This is a primitive 'for' cycle, but it will do. (In gnuplot 4.3, the option 'for' was introduced in the 'plot' command, but that would not do too much good here, for we still have got to figure out the actual numbers.)
With these in mind, we write the following two scripts, the first of which named pie.gnu
reset os=1.3 FIT_LIMIT=1e-8 L=6.0 f(x,a)=(x>a-0.5?(x<a+0.5?b:0):0) r(x)=abs(2*x-0.5); g(x)=sin(x*pi); b(x)=cos(x*pi/2.0) set view 30, 20 set parametric set isosample 2, 2 unset border unset tics unset key set ticslevel 0 unset colorbox set urange [0:1] set vrange [0:1] set xrange [-2:2] set yrange [-2:2] set zrange [0:3] A=0.0; D=0.0 set multiplot # First, we draw the 'box' around the plotting volume set palette model RGB functions 0.9, 0.9,0.95 splot -2+4*u, -2+4*v, 0 w pm3d set palette model RGB functions 0.8, 0.8, 0.85 splot cos(u*2*pi)*v, sin(u*2*pi)*v, 0 w pm3d call 'pie_r.gnu' unset multiplot
while the second one named 'pie_r.gnu'
unset parametric b=0.3 set yrange [*:*] fit [0:L] f(x,D) 'pie.dat' u 0:2 via b B=b fit [0:L] f(x,D) 'pie.dat' u 0:1 via b D=D+1.0 set palette model RGB functions r(D/L), g(D/L), b(D/L) set parametric set yrange [-2:2] set urange [A:A+B] set label 1 "%g", b at os*cos(2*pi*(A+B/2.0)), os*sin(2*pi*(A+B/2.0)), 0.2 cent splot cos(u*2*pi)*v, sin(u*2*pi)*v, 0.2 w pm3d A=A+B if(D<L) reread
Now, let us see what is happening here. In the first script, 'os' will be used to place the labels later on. The gnuplot variable FIT_LIMIT is set to that value, so that the fit values are more accurate. It might be necessary to change it, if your labels are not what you expect. For the arcs, it should not really matter, because the default value is going to be accurate enough for any practical plots. 'L' is the number of data that we have (note that data are numbered starting with 0). Next, we define 4 functions. The first one is our fit function, the other three are used to colour the arcs. You can change these, if you are not satisfied with the colour scheme that you get. Any three functions will do, which are defined on [0:1], and return with a value in [0:1]. You can read about this in the post in which I discussed phonged surfaces, sometime in late May.
The next couple of lines set up the various ranges of our plot. I wrote about this in my first pie chart post, and the lines giving the background of the plot should also be familiar from that post. 'A' and 'D' are our control variables that we manipulate in 'pie_r.gnu'. We then draw the shadow of the pie, and finally, call 'pie_r.gnu'.
Let us take a look at 'pie_r.gnu'. First, we extract the value in the second column, and then in the first one. We will use this latter one to produce the label. Note that we have got to unset the parametric plot, otherwise, the fitting function would not work. Also note that we re-set the yrange. This is necessary, because the actual plot is in the [-2:2] range, while the fit is on values around 1990. Then we increment the value 'D' (this is the ordinal number of the row that we are currently processing), and re-set our palette, using the three functions, r(x), g(x), and b(x) that we defined in 'pie.gnu'. Then, using the extracted values, we set the range of the parametric plot, and define the label, and plot the arc. Finally, we check, if we have called the script enough times. Loading 'pie.gnu' will produce the following graph:
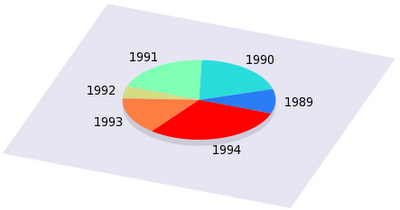
A couple of comments about this script: as I already mentioned, you can change the colour scheme by using various functions. However, if you are really lazy, you can simply generate three random numbers by
r=rand(0); g=rand(0); b=rand(0)
and assign these values to the next palette.
Second, you can easily implement an "explosion", by shifting one or several of the arcs by shift*cos(2*pi*(A+B/2)) and shift*sin(2*pi*(A+B/2)), based on some condition that you set. It should not be hard, either, to plot a real 3D pie char based on the scheme that I outlined about two months ago.
Third, if the sum of your numbers is not normalised to one, you can easily fix it by adding an extra loop to your script: if you have a script called 'pie_r2.dat', containing
unset parametric b=0.3 set yrange [*:*] fit [0:L] f(x,D) 'pie.dat' u 0:2 via b D=D+1.0 G=G+b if(D<L) reread
and call this in 'pie.gnu' immediately before 'pie_r.gnu', then 'G' will just be the sum of all numbers in column 2, and you can use this to normalise the numbers when you call 'pie_r.gnu'.
And last, the only thing you need in advance is the number of records you want to process, 'L'. This is the only thing you have to set by hand, all the rest is automatic. If you want to learn how to avoid this small "difficulty", you should read the post on the 2nd of August.
I hope that this script can convince people that we haven't got to rely on any outside tool, and can still produce a decent pie chart in gnuplot.I also feel that this approach is, in some sense, much cleaner, than the one that was based on gawk. Some people will probably contest this statement, but doing everything in gnuplot ensures that we retain the platform independence.
Really love the Blog. Some very useful tips.
ReplyDeleteMany thanks for visiting! Also, if you have any ideas as to what else should be implemented, please, let me know! I would be more than happy to work on them! Cheers,
ReplyDeletegnuplotter
Great blog ;). I've been rewriten your last bash code to php.
ReplyDeleteSource: http://wklej.to/Bnb4
I had to change data file(I need spaces in labels sometimes) and now it looks like:
First label;0.3
Second label;0.5
Third label;0.2
Using:
gnuplot> load "< php ./pie.php pie.dat"
:)
Working link: http://wklej.to/BNb4 ;)
ReplyDeleteHi Hellson,
ReplyDeleteThanks for the feedback! I will insert a link to your script in the relevant pages.
Cheers,
Gnuplotter
I'd like to see a 2d pie chart, do you have some idea ?
ReplyDeleteI think I don't understand the question: you are commenting on a page on pie charts, and ask how to make one. Did you mean 3D pie charts? There are a couple of blog posts discussing this, just search for them on this page.
ReplyDeleteCheers,
Zoltán
It does not work for me. :-( I am very new to gnuplot and do not understand the script very well, but you might still be interested. I am using Windows XP.
ReplyDeleteThis is what gets printed:
--------------------------
gnuplot> load 'pie.gnu'
Warning: empty cb range [0:0], adjusting to [-1:1]
Warning: empty cb range [0:0], adjusting to [-1:1]
Iteration 0
WSSR : 0.235 delta(WSSR)/WSSR : 0
delta(WSSR) : 0 limit for stopping : 1e-008
lambda : 0.408248
initial set of free parameter values
b = 0.3
/
Iteration 1
WSSR : 0.195816 delta(WSSR)/WSSR : -0.200104
delta(WSSR) : -0.0391837 limit for stopping : 1e-008
lambda : 0.0408248
resultant parameter values
b = 0.128571
/
Iteration 2
WSSR : 0.195 delta(WSSR)/WSSR : -0.00418628
delta(WSSR) : -0.000816324 limit for stopping : 1e-008
lambda : 0.00408248
resultant parameter values
b = 0.100048
/
Iteration 3
WSSR : 0.195 delta(WSSR)/WSSR : -1.15899e-008
delta(WSSR) : -2.26003e-009 limit for stopping : 1e-008
lambda : 0.000408248
resultant parameter values
b = 0.1
************************
After 4 iterations the fit converged.
final sum of squares of residuals : 0.195
rel. change during last iteration : 0
degrees of freedom (FIT_NDF) : 5
rms of residuals (FIT_STDFIT) = sqrt(WSSR/ndf) : 0.197484
variance of residuals (reduced chisquare) = WSSR/ndf : 0.039
Final set of parameters Asymptotic Standard Error
======================= ==========================
b = 0.1 +/- 0.1975 (197.5%)
correlation matrix of the fit parameters:
b
b 1.000
Read 6 points
Skipped 6 points outside range [z=0:3]
No data to fit
multiplot>
---------------------
/MagnusG
Could you, please, post the data file, too? It is not what I gave here, at least, your numbers seem to be different.
ReplyDeleteCheers,
Zoltán
Here is the data file (pie.dat):
ReplyDelete1989 0.1
1990 0.2
1991 0.2
1992 0.05
1993 0.15
1994 0.3
I use gnuplot 4.4 patchlevel 0-rc1 on Windows XP.
/MagnusG
Great blog! very helpful.
ReplyDeleteEverything is working but when I modify the labels in the pie.dat file from numbers (1990, etc.) to words, I get an error.
I tried modifying the line:
fit [0:L] f(x,D) 'pie.dat' u 0:1 via b
but so far no success. Could you please help me with that?
Many thanks!
Hi,
ReplyDeleteIs there a reason you deleted my comment? I need help with creating the pie charts with string labels instead of numbers. Any hints?
Thanks.
I don't usually delete comments, unless there are in a language that I don't speak. Since some of the (probably Chinese) comments pointed to various sex-related web pages, I decided to remove them all.
ReplyDeleteI am sorry, if your remarks fell victim to this purification process. As a general rule, I will delete all comments that are not in English, German, Hungarian, or Russian. I would, however, like to encourage people to post questions/requests/comments in English, for that is the language of the blog.
As for your second question, you can use the stringcolumn modified to plot strings instead of numbers. In fact, a relatively recent post on pie charts shows this. The post itself is gnuplot 4.4 related, but this particular feature works in older versions of gnuplot.
I hope this helps,
Zoltán
Hi,
ReplyDeleteyour posts were very helpfull, thanks so much
I have posted the php script I made for my project where pies were needed,
(just 2D pies) if it can be helpfull
http://openlemon.blogspot.com/2010/11/draw-pie-with-gnuplot.html
Hi Lemon,
ReplyDeleteMany thanks for sharing the code! I am sure it is going to prove useful.
Cheers,
Zoltán
Excellent page. I am having trouble running the script, though.
ReplyDeleteI'm on MacOS 10.5.6 with gnuplot 4.2
I get the warning:
Warning: empty cb range [0:0], adjusting to [-1:1]
And the plot is just a square. Is there something I need to update?
Thanks,
Physics Josh
replacing
ReplyDeletefit [0:L] f(x,D) 'pie.dat' u 0:1 via b
with
fit [0:L] f(x,D) 'pie.dat' u 0:($$1*0.001) via b
solved the problem in a very roughly for me
and following multiplying by 1000 b when printing labels
ReplyDeleteset label 1 "%g", b*1000 at os*cos(2*pi*(A+B/2.0)), os*sin(2*pi*(A+B/2.0)), 0.2 cent